Tree Data Structure
A tree is a nonlinear data structure in which the elements are arranged in a sorted sequence. Trees are used to represent a hierarchical relationship that exists among several data items.
Trees are very flexible, important, versatile, and powerful data structures.
Tree Terminologies
Node
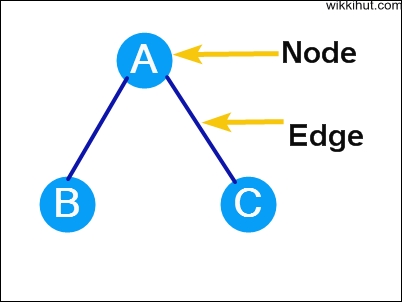
Each data item in a tree is called a node. A node is an entity that contains a key or a value and has pointers to its child nodes.
The last nodes of each path are called leaf nodes or external nodes that do not contain a link/pointer to child nodes or it has no child nodes.
The node having at least a child node is called an internal node.
Edge
It is the line drawn from one node to another node or it is the link between any two nodes.
Root
It is the topmost node of a tree. It is the first in the hierarchical arrangement of data items on the top of the tree.
Height of a Node
The height of a node is the number of edges from the node to the deepest leaf. Height is the longest path from the node to a leaf node.
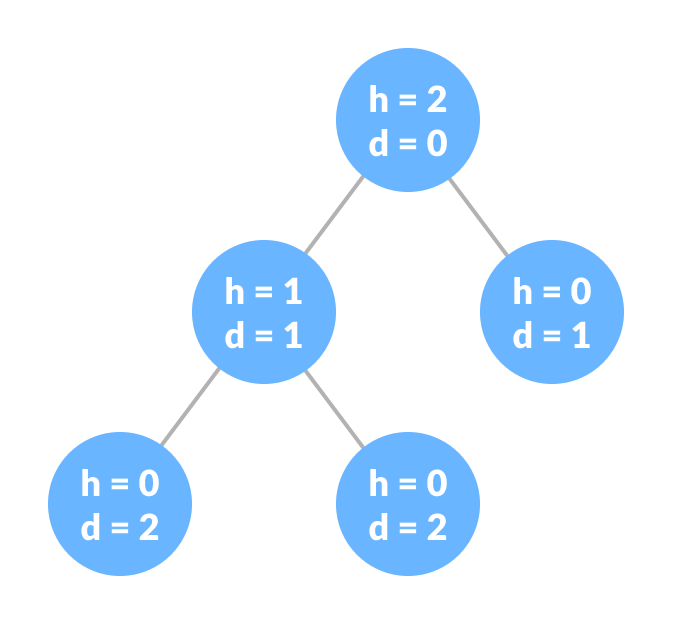
Depth of a Node
The depth of a node is the number of edges from the root to the node. It is the maximum level of any node in a given tree.
Terminal Node
A node with degree zero is called a terminal node or a leaf. It is a node that has no child nodes.
Siblings
All the children nodes of a given parent node are called siblings. They are also called brothers.
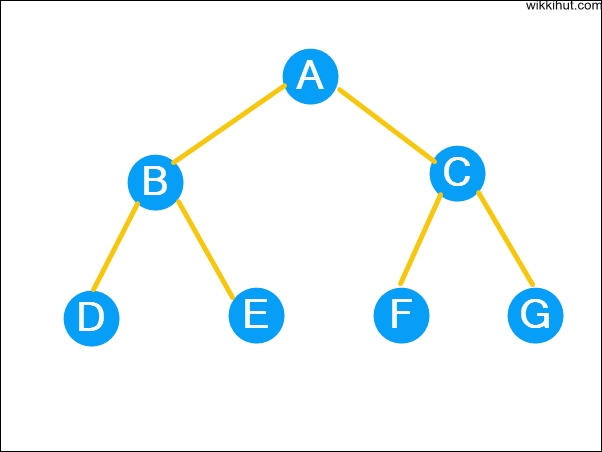
- B and c are siblings for parent node a.
- E and F are siblings of parent node d.
Path
The path is a sequence of consecutive edges from the source node to the destination node. In the figure above, the path between A and E is given by the node pairs, (A, B), (B, E).
Height of a Tree
The height of a Tree is the height of the root node or the depth of the deepest node.
Degree of a Node
The degree of a node is the total number of branches of that node.
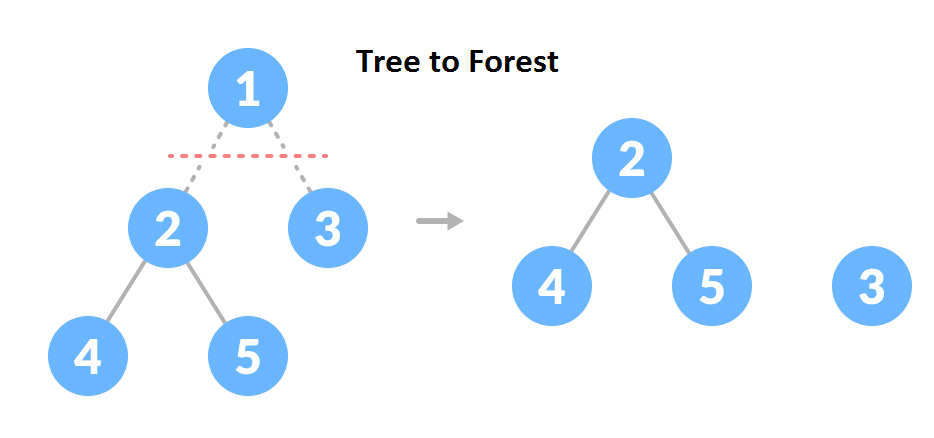
Forest
A collection of disjoint trees is called a forest. You can create a forest by cutting the root of a tree.
Types of Trees
- Binary Tree
- Binary Search Tree
- AVL Tree
- B-Tree
Tree Traversal
In order to perform any operation on a tree, you need to reach a specific node. So visiting the nodes in a particular pattern is called tree traversal.
Here are some tree traversal algorithms which traverse the tree nodes in a particular order.
- Pre Order
- In Order
- Post Order
Tree Applications
- Decision-based algorithm is used in machine learning which uses algorithm of tree.
- Indexing in databases is used by tree data structure.
- Binary Search Trees (BSTs) are used to quickly check whether an element is present in a set or not.
- Heap is a kind of tree that is used for heap sort.
- A modified version of a tree called Tries is used in modern routers to store routing information.
- DNS system also uses it.
- Most popular databases use B-Trees and T-Trees, which are variants of the tree structure we learned above to store their data
- Compilers use a syntax tree to validate the syntax of every program you write.
Why Tree Data Structure?
Because the other data structures such as Arrays, Linked Lists, Stack, and Queue are linear data structures that store data sequentially.
The time complexity increases with the increase in the data size in the linear data structures during any program operation so to overcome this problem we use nonlinear data structures, such as trees and graphs.
These data structures allow quicker and easier access to the data. Because the time complexity of tree traversal is better than any linear data structure.
The tree is a nonlinear data structure. It is a collection of nodes that are related to each other.
The lines connecting elements or nodes are called branches or edges.
The visiting of a particular node in a tree is called tree traversal.
There are 3 main types of tree traversal.
1. Pre Order
2. In Order
3. Post Order
.