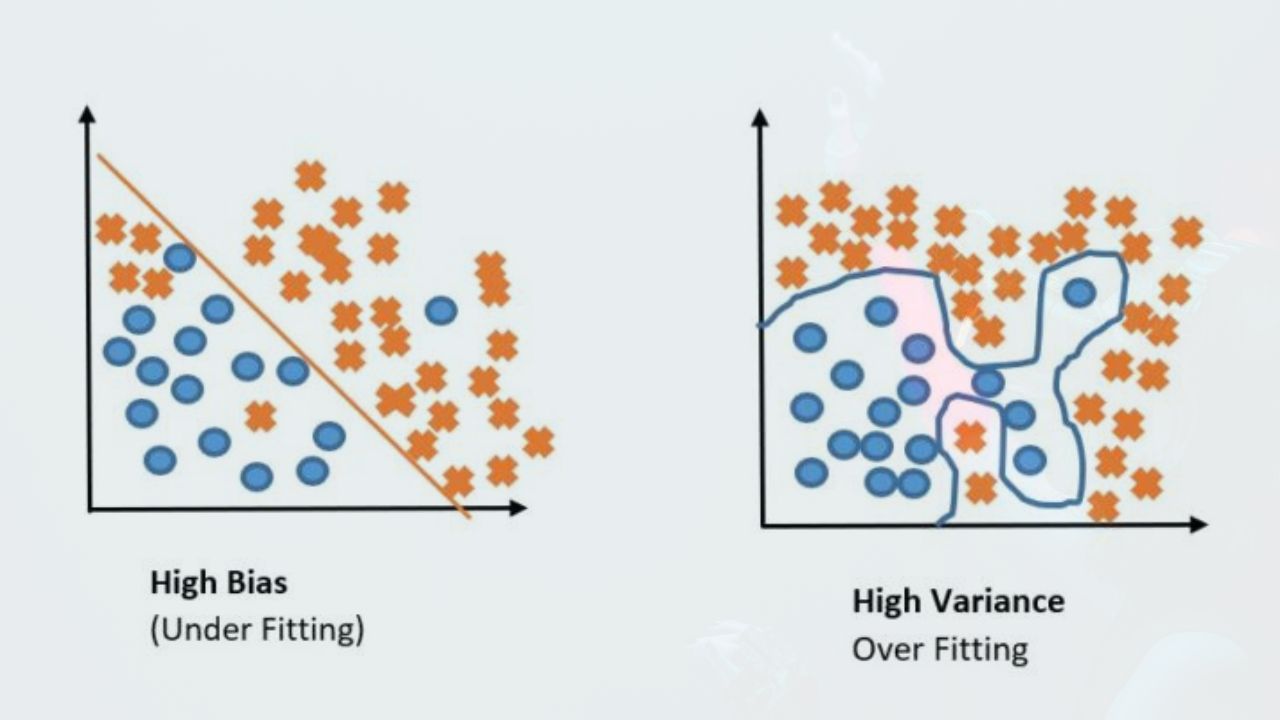
What is Bias: Let’s first look at the dictionary meaning of Bias. Bias is prejudice for or against one person or group, especially in a way considered to be unfair. Now I will explain to you what is Bias in Machine Learning:
Bias:
Bias is a process that occurs when a model produces results that are systemically prejudiced due to erroneous assumptions in the machine learning process. Bias measures how much expected values varies from the correct values.
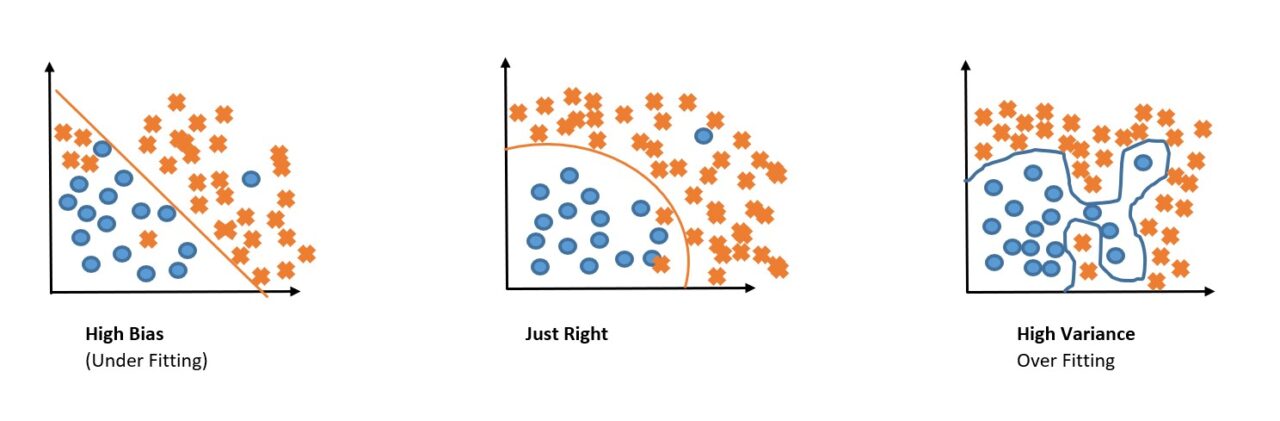
So, if you look at the first example in the image below, we can say that a Model underfits the data if it has high Bias. Or we can say if a model has low Bias, it well predicts the labels of the training dataset.
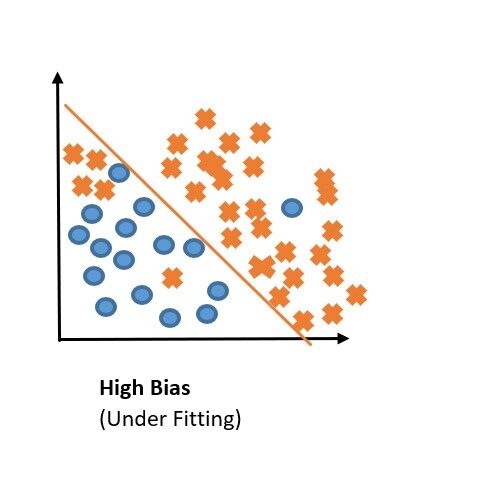
Underfitting:
Underfitting is the inability of the model to predict well the labels of the data it was trained on. So, Bias is the process that decides whether a model underfits or not.
Some of the reasons that are responsible for High Bias or (underfitting) are:
- A model which is too simple for the data (for example a linear model can often underfit).
- Training set error is high. Or, The features are not informative enough for the model.
I will explain the second reason with an example as: Let’s say you want to predict whether an animal is a cat or dog. And the features you have are colour, number of legs, tail, etc. Clearly these features are not good classifiers for the two animals, so the model can not be able to differentiate between the two.
To counter the problem of high bias we use a more complex model or reduce the training set error. But if the model is too complex another problem occurs which is called Variance.
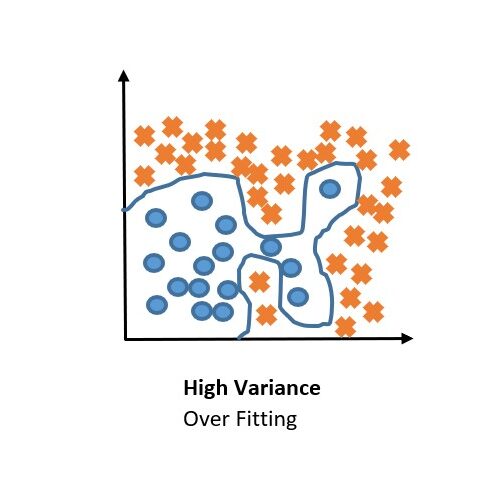
Variance:
The Variance is the sensitivity of a model towards different parts of the training set. Simply stated, Variance means how the model behaves when using different portions of the data set.
Variance measure how much on average, the mean square error varies around the expected value on going from one dataset to another. (from training dataset to validation dataset).
Overfitting:
Overfitting is problem that occurs with High Variance, the model that overfits predicts very well the training data but poorly predicts the validation data set or development data set.
Overfitting is the process in which the model predicts very well labels of the examples used during training, i.e., the model learns very tiny details of the training data but when applied to examples that weren’t seen during training it makes frequent errors.
Some of the important reasons that are responsible for overfitting are as:
- The model is too complex for the data.
- The dataset has too many features but a small number of training examples.
Bias and Variance are almost inverse to each other, i.e., High bias implies low variance and vice versa. It is much difficult to have a model that has low bias as well as low variance.
FAQ’S
What is Bias?
Bias is a process that occurs when a model produces results that are systemically prejudiced due to erroneous assumptions in the machine learning process. Bias measures how much expected values varies from the correct values.
What is Variance in Machine learning?
The Variance is the sensitivity of a model towards different parts of the training set. Simply stated, Variance means how the model behaves when using different portions of the data set
What is Overfitting in machine learning?
Overfitting is the process in which the model predicts very well labels of the examples used during training, i.e., the model learns very tiny details of the training data but when applied to examples that weren’t seen during training it makes frequent errors.