
In machine learning, we use precision and accuracy to measure how good a model is at making predictions.
- Precision tells us how often the model is right when it predicts something as positive.
- Accuracy, on the other hand, tells us how often the model is correct overall.
If a model has high precision, it means it’s good at avoiding false inputs. Accuracy, on the other hand, looks at the overall correctness of the model’s predictions.
What is Precision and Accuracy?
Precision refers to the closeness of individual measurements or predictions to each other. It assesses the consistency and reliability of the results.
Accuracy, on the other hand, measures the proximity of those measurements or predictions to the true or desired value, indicating how well the model performs overall.
While precision focuses on minimizing variation within the data, accuracy emphasizes minimizing the overall error between the predicted and actual values.
Both precision and accuracy are important for evaluating and improving machine learning models.
Also Read: Machine Learning Types
Why Accuracy or Precision in Machine Learning?
Once we have trained a model using a learning algorithm, we need to evaluate its performance.
We use a separate test dataset to assess how well the model performs on unseen data. If the model performs well on the test data, we consider it to be a good model.
We utilize metrics such as accuracy and precision to assess the performance of a classification model. By using these metrics, we can better understand how well the model is performing.
Accuracy and precision are important measures to evaluate the performance of a classification model. Accuracy gives us an overall picture of correctness, while precision specifically focuses on accurate positive predictions.
To gain a deeper comprehension of accuracy and precision, it is essential to familiarize ourselves with the concept of the confusion matrix—a pivotal tool in classification model evaluation.
Let’s explore these metrics one by one, delving into their significance and implications.
Must Read: ML Beginner Project Ideas
Confusion Matrix:
The confusion matrix is a table that shows how well our model predicts examples from different classes. One axis of the table shows the actual labels and another axis shows the predicted labels.
To better understand this let us take an example of a model that predicts two classes: “spam” and “not spam”.
| Spam (Predicted) | Not spam (predicted) | |
| Spam (actual) | 28 (TP) | 2 (FN) |
| Not Spam (actual) | 22 (FP) | 578 (TN) |
The above confusion matrix predicts 28 out of 30 actual spam examples correctly.
This means that we have 28 true positives or TP = 28. The model predicts 2 examples incorrectly as Not Spam, in this case, we have 2 false negatives or FN = 2.
Similarly, out of 600 actual Not Spam examples, the model correctly predicts 578 as Not Spam, so we have 578 true negatives OR TN = 578 and the model incorrectly predicts 22 examples as spam, so we have 22 false positives or FP = 22.
If we have a multiple-class classification model, then our confusion matrix will have multiple rows and columns.
Of the confusion matrix, we can easily determine the mistake patterns, and we can decide whether we should add more labeled examples or should we add more features.
Now with the help of this confusion matrix, we can calculate the Accuracy and Precision of the model.
Accuracy:
Accuracy is given by the ratio of correctly classified examples to the total number of classified examples.
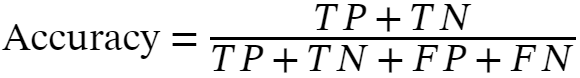
1. Accuracy
Let’s calculate the accuracy of the model using the above confusion matrix:
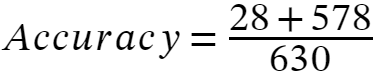
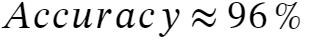
Accuracy is a helpful measure when it’s equally important to predict errors in all categories. In the case of Spam/Not-Spam, accuracy may not be the most suitable metric.
For example, we can tolerate false positives less than false negatives, this is the case when someone sends you an important email and your model filters it as spam and does not show it to you.
On the other hand false negatives is not a big problem, because if your model doesn’t detect a small percentage of spam mail it is not a problem.
Precision/Recall:
Precision and Recall are the two important metrics that are used to assess the classification model. I am mentioning recall alongside precision because recall and precision are complementary to each other.
It is important to understand both metrics in order to have a comprehensive understanding of the evaluation of classification models. So, let’s understand them one by one.
Precision focuses on the proportion of correctly predicted positive instances out of all predicted positive instances.
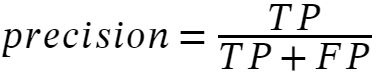
The recall is the ratio of correct positive predictions to the overall number of positive examples in the dataset:
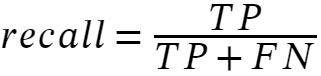
Precision is the ratio of correct positive predictions to the overall number of positive predictions, while recall focuses on the proportion of correctly predicted instances out of all actual positive instances.
Precision and recall exhibit an inverse relationship, where enhancing precision often leads to a decline in recall, and vice versa. This trade-off arises from their distinct focuses:
Precision aims to minimize false positives (misclassifying negative instances as positive), while recall strives to minimize false negatives (misclassifying positive instances as negative).
Consequently, attaining high precision usually involves sacrificing some recall, and achieving high recall often means sacrificing some precision.
This delicate balance between precision and recall is a crucial aspect to consider when evaluating classification models.
By understanding both metrics, we can gain deeper insights into the performance and limitations of these models in different scenarios.
FAQ’s
What is Accuracy in Machine Learning?
Accuracy is given by the ratio of correctly classified examples to the total number of classified examples. Accuracy is a helpful measure when it’s equally important to predict errors in all categories
What is Precision in Machine Learning?
Precision is the ratio of correct positive predictions to the overall number of positive predictions. Precision aims to minimize false positives.
What is Recall in Machine Learning?
The recall is the ratio of correct positive predictions to the overall number of positive examples in the dataset:
What is a confusion matrix in machine learning?
The confusion matrix is a table that shows how well our model predicts examples from different classes. One axis of the table shows the actual labels and another axis shows the predicted labels.